
 Zadatak
Zadatak
Dati .csv fajlovi sadrže podatke koji odgovaraju šemi sa slike.
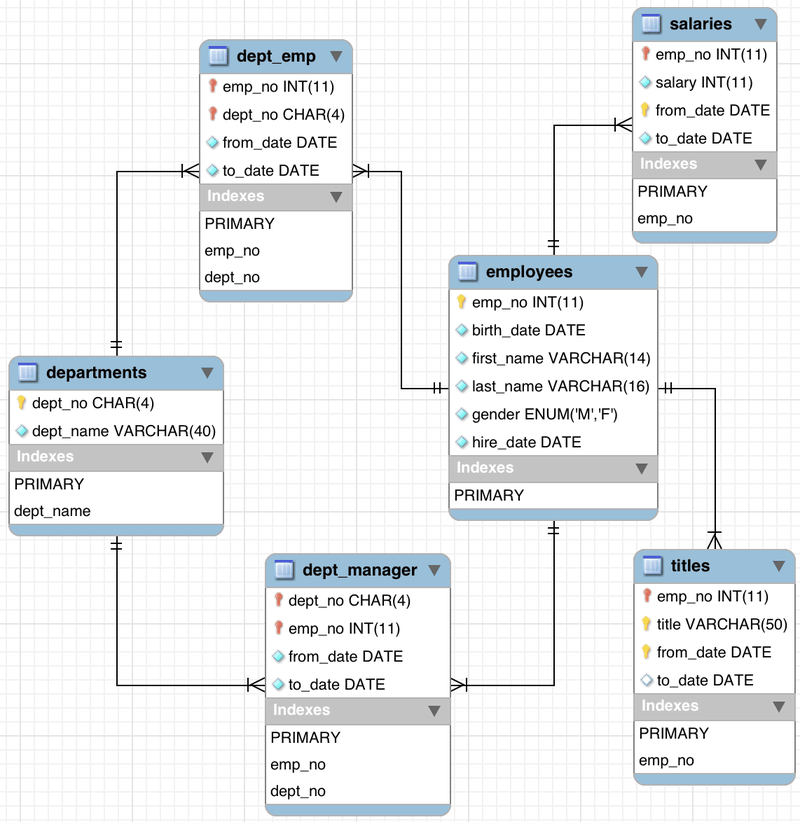
Napisati jednu pySpark skriptu koja:
(ime, prezime, godina, suma novca),
(ime, prezime)
(imeRadnika, prezimeRadnika, imeDepartmana, imeMenadžera, prezimeMenadžera)
(imeDepartmana, kolicinaNovca)
Primer učitavanja jednog .csv fajla u odgovarajući RDD
>>> import csv
>>> from datetime import datetime
>>> csvRDD = sc.textFile("dept_emp.csv").mapPartitions(lambda x: csv.reader(x))
>>> deptEmp = csvRDD.map(lambda (empt_no, dept_no, from_date, to_date): (empt_no + " " + dept_no, (datetime.strptime(from_date, "%Y-%M-%d").date(), datetime.strptime(to_date, "%Y-%M-%d").date()))).partitionBy(4).cache()
>>> print deptEmp.toDebugString()
>>> deptEmp.first()Rešenja -> radnici.py:
import csv
from datetime import datetime
from pyspark import SparkConf, SparkContext
def getRDDfromCSV(csvPath):
return sc.textFile(csvPath).mapPartitions(lambda x: csv.reader(x))
def dajZaraduPoGodini(empt_no, salary, from_date, to_date):
# Kreiraj datume iz stringova
from_date = datetime.strptime(from_date, "%Y-%M-%d").date()
to_date = datetime.strptime(to_date, "%Y-%M-%d").date()
# Uzmi godine pocetnog i krajnjeg datuma
fromYear = from_date.year
toYear = from_date.year
empt_no = int(empt_no)
# Izracunaj zaradu po danu
zaradaPoDanu = float(salary) / 365
# Ako je plata vazila u toku jedne godine (primer : 2010-10-01 - 2010-31-12)
if fromYear == toYear:
ukupnaZarada = zaradaPoDanu * (to_date - from_date).days
return ((empt_no, fromYear), ukupnaZarada)
else: # na Primer 2010-10-5 - 2011-10-5
'''
Broj radnih dana u prvoj godini
od 2010-10-5 do 2010-12-31
'''
brojDana1 = zaradaPoDanu * (datetime.strptime(str(fromYear) + "12-31", "%Y-%M-%d").date() - from_date).days
zaradaUPrvojGodini = brojDana1 * zaradaPoDanu
'''
Broj radnih dana u drugoj godini
od 2011-1-1 do 2011-10-5
'''
brojDana2 = zaradaPoDanu * (to_date - datetime.strptime(str(toYear) + "1-1", "%Y-%M-%d").date()).days
zaradaUDrugojGodini = brojDana2 * zaradaPoDanu
return (
((empt_no, fromYear), zaradaUPrvojGodini), # Prva godina
((empt_no, toYear), zaradaUDrugojGodini) # Druga godina
)
def zadatak1():
# Ucitaj sirove podatke plata u RDD
rddSalaries = getRDDfromCSV("salaries.csv")
'''
Napravi parove sa sledecim sadrzajem:
kljuc -> (empt_no, year)
vrednost -> zarada
Funkcija moze vratiti jedan ili dva para.
1. Jedan par se vraca u slucaju kada imamo npr. od 2010-10-01 do 2010-31-12
2. Dva para se vracaju u slucaju kada je plata za period u toku dve razlicite godine:
od 2010-10-5 do 2011-10-5
'''
salariesPerYear = rddSalaries.map(lambda (empt_no, salary, from_date, to_date):
dajZaraduPoGodini(empt_no, salary, from_date, to_date)).partitionBy(4).cache()
# Za zvakog zaposlenog i godinu izracunaj platu
sumSalariesPerYear = salariesPerYear.reduceByKey(lambda x, y: x + y)
# Postavi "empt_no" kao kljuc radi spajanja sa kolekcijom "employee" po kljucu "empt_no"
sumSalariesPerYear = sumSalariesPerYear.map(lambda ((empt_no, year), salaryPerYear):
(
empt_no, # key
(year, salaryPerYear) # value
)
)
# Ucitaj sirove podatke radnika u RDD
rddEmployees = getRDDfromCSV("employee.csv")
rddEmployees = rddEmployees.map( lambda (empt_no, birth_date, first_name, last_name, gender, hire_date) :
(
int(empt_no), # key
first_name + " , " + last_name # value
)
)
# Vrati rezultat prema formatu koji se trazi u zadatku
return sumSalariesPerYear.join(rddEmployees).map(lambda (key, ((year, salary), name)):
(name, year, salary))
def daLiSePlataSmanjivala(empt_no, salariesPairIterable):
salaryTmp = -1
for sp in sorted(salariesPairIterable): # sortira se za slucaj da u csv vec nije sortirano
salary = sp[1]
if salary < salaryTmp:
return False
else:
salaryTmp = salary
return True
def zadatak2():
# Ucitaj sirove podatke plata u RDD
rddSalaries = getRDDfromCSV("salaries.csv")
salariesPerEmployee = rddSalaries.map(lambda (empt_no, salary, from_date, to_date):
(
int(empt_no), # key
( # value
datetime.strptime(from_date, "%Y-%M-%d").date(),
float(salary)
)
)
).partitionBy(4).cache()
# Grupisi sve plate po korisniku
salariesPerEmployee = salariesPerEmployee.groupByKey()
# Za svakog radnika proveri da li se plata smanjivala
salariesPerEmployee = salariesPerEmployee.filter(lambda (empt_no, salariesPairIterable) :
daLiSePlataSmanjivala(empt_no, salariesPairIterable))
# Ucitaj sirove podatke radnika u RDD
rddEmployees = getRDDfromCSV("employee.csv")
# Napravi parove kojima se svako ime i prezime identifikuje id-em zaposlenog (empt_no)
rddEmployees = rddEmployees.map( lambda (empt_no, birth_date, first_name, last_name, gender, hire_date) :
(
int(empt_no), # key
(first_name, last_name) # value
)
)
return salariesPerEmployee.join(rddEmployees).map(lambda (empt_no, (salariesPairIterable, (name, surename))) :
(name, surename))
if __name__ == "__main__":
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf=conf)
'''
Za svakog zaposlenog racuna ukupnu sumu novca koju je primao po godinama. Razultat treba da bude u obliku
(ime, prezime, godina, suma novca)
'''
rez1 = zadatak1()
#print rez1.take(10)
'''
Pronalazi radnike kojima se plata nikada nije smanjivala. Rezultat je oblika:
(ime, prezime)
'''
rez2 = zadatak2()
print rez2.take(10)