
 Partitions
Partitions
RDD je veliki skup podataka. Te kolekcije podataka su često toliko velike da ne mogu da stanu na jednom čvoru. U takvim slučajevima podaci moraju da budu podeljeni na više čvorova. Spark automatski partiocioniše podatke po čvorovima.
| Osobina | Opis |
|---|---|
| RDD.getNumPartitions() | Broj particija |
| RDD.partitioner | Ako postoji vraća partitioner (HashPartitioner, RangePartitioner, CustomPartitioner) |
| sc.defaultParallelism | Defoltni nivo paralelizma definisan u SparkContext |
Spark koristi partiotioner kao algoritam za utvrđivanje na kom čvoru se nalazi specifični podatak. Ako partitioner ima vrednost NONE onda podaci nisu klasifikovani na osnovu karakteristika podataka, već su nasumično distribuirani i uniformno raspoređeni po čvorovima.
Generički RDD
| Api poziv | Veličina particije u rezultujućem RDD-u | Koji partitioner je korišćen |
|---|---|---|
| sc.parallelize() | sc.defaultParallelism | NONE |
| sc.textFile() | sc.defaultParallelism ili broj blokova fajla, šta god je veće | NONE |
| filter(), map(), flatMap(), distinct() | Isto kao i roditelj RDD | NONE, osim filter koji koristi partitioner roditeljskog RDD-a |
| rdd.union(otherRDD) | rdd.partiotions.size+otherRDD.partitions.size | NONE |
| rdd.intersection(otherRDD) | max(rdd.partiotions.size,otherRDD.partitions.size) | NONE |
| rdd.subtract(otherRDD) | rdd.partiotions.size | NONE |
| rdd.cartesian(otherRDD) | rdd.partiotions.size*otherRDD.partitions.size | NONE |
pair RDD
| Api poziv | Veličina particije u rezultujućem RDD-u | Koji partitioner je korišćen |
|---|---|---|
| reduceByKey(), foldByKey(), combineByKey(), groupByKey() | Isto kao i roditelj RDD | HashPartitioner |
| sortByKey() | Isto kao i roditelj RDD | RangePartitioner |
| mapValues(),flatMapValues() | Isto kao i roditelj RDD | Roditeljski RDD partitioner |
| cogroup(), join(), leftOuterJoin(), rightOuterJoin() | Zavisi od osobina RDD-a | HashPartitioner |
Neka je dat fajl korisnici.txt koji sadrži informacije o korisnicima u sledećem formatu (UserID, UserInfo), gde UserID predstavlja jedinstveni identifikator korisnika, a UserInfo predstavlja listu kategorija na koje je korisnik pretplaćen. Aplikacija periodično kombinuje ove podatke sa manjim fajlom koji reprezentuje događaje koji su se dogodili u poslednjih pet minuta. Manji fajlovi se zovu ulaz1.txt, ulaz2.txt, … Podaci su oblika (UserID, LinkInfo) - UserID korisnika koji je kliknuo na link iz kategorije LinkInfo.
Za svaki manji fajl pojedinačno je potrebno prebrojati koliko korisnika je posetilo link (LinkInfo) koji nije u nekoj od kategorija na koje je korisnik pretplaćen (UserInfo).
Predlog generatora podataka
import os
import shutil
from random import random, randint, seed
from pyspark import SparkConf, SparkContext
import sys
if __name__ == "__main__":
# brojKategorija = 10, brojKorisnika = 100000, brojKlikova = 1000
if len(sys.argv) != 4:
print "Sintaksa spark-submit generatorUserData.py <brojKategorija> <brojKorisnika> <brojKlikova>"
exit(1)
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
pathKorisnici = os.path.join(os.getcwd(), "korisnici")
pathUlazi = os.path.join(os.getcwd(), "ulazi")
if os.path.exists(pathKorisnici):
shutil.rmtree(pathKorisnici)
if os.path.exists(pathUlazi):
shutil.rmtree(pathUlazi)
brojKategorija = int(sys.argv[1])
brojKorisnika = int(sys.argv[2])
brojKlikova = int(sys.argv[3])
seed(None)
def genKorisnici(x):
lista = ""
for i in xrange(brojKategorija):
if random() < 0.5:
lista += " " + str(i)
return str(x) + " " + lista
def genKlik(x):
korisnik = randint(0, (brojKorisnika - 1))
kategorija = randint(0, (brojKategorija - 1))
return str(korisnik) + " " + str(kategorija)
korisniciRDD = sc.range(0, brojKorisnika, 1, 1).map(genKorisnici)
korisniciRDD.saveAsTextFile(pathKorisnici)
ulaziRDD = sc.range(0, 4 * brojKlikova, 1, 4).map(genKlik)
ulaziRDD.saveAsTextFile(pathUlazi)
allKorisnici = os.listdir(pathKorisnici)
for fajl in allKorisnici:
if fajl.startswith(".") or fajl.startswith("_"):
os.remove(os.path.join(pathKorisnici, fajl))
else:
os.rename(os.path.join(pathKorisnici, fajl), os.path.join(pathKorisnici, "korisnici.txt"))
i = 0
allUlazi = os.listdir(pathUlazi)
for fajl in allUlazi:
if fajl.startswith(".") or fajl.startswith("_"):
os.remove(os.path.join(pathUlazi, fajl))
else:
i = i + 1
ime = "ulazi" + str(i) + ".txt"
os.rename(os.path.join(pathUlazi, fajl), os.path.join(pathUlazi, ime))Predlog rešenja
def processNewLogs(fileName, sc, userData):
events = sc.textFile(fileName).map(lambda x: (x.split(" ")[0], x.split(" ")[1:]))
joined = userData.join(events)
offTopic = joined.filter(lambda (userId, (userInfo, linkInfo)): linkInfo not in userInfo).count()
return offTopic
userData = sc.textFile("korisnici.txt").map(lambda x: (x[0], x[1:])).persist()
processNewLogs("ulaz1.txt", sc, userData)
processNewLogs("ulaz2.txt", sc, userData)
processNewLogs("ulaz3.txt", sc, userData)
processNewLogs("ulaz4.txt", sc, userData)Prethodni kod daje dobar rezultat, ali je neefikasan. Operacija join(), koja se poziva svaki put kada se pozove processNewLogs() ne zna ništa o tome kako su raspoređene particije. Ova operacija će prerasporediti ključeve iz oba RDD preko mreže tako da isti ključevi budu na jednom čvoru. Pošto očekujemo da će RDD userData da sadrži mnogo više podataka u odnosu na events RDD ovo je nepotrebno slanje podataka preko mreže.
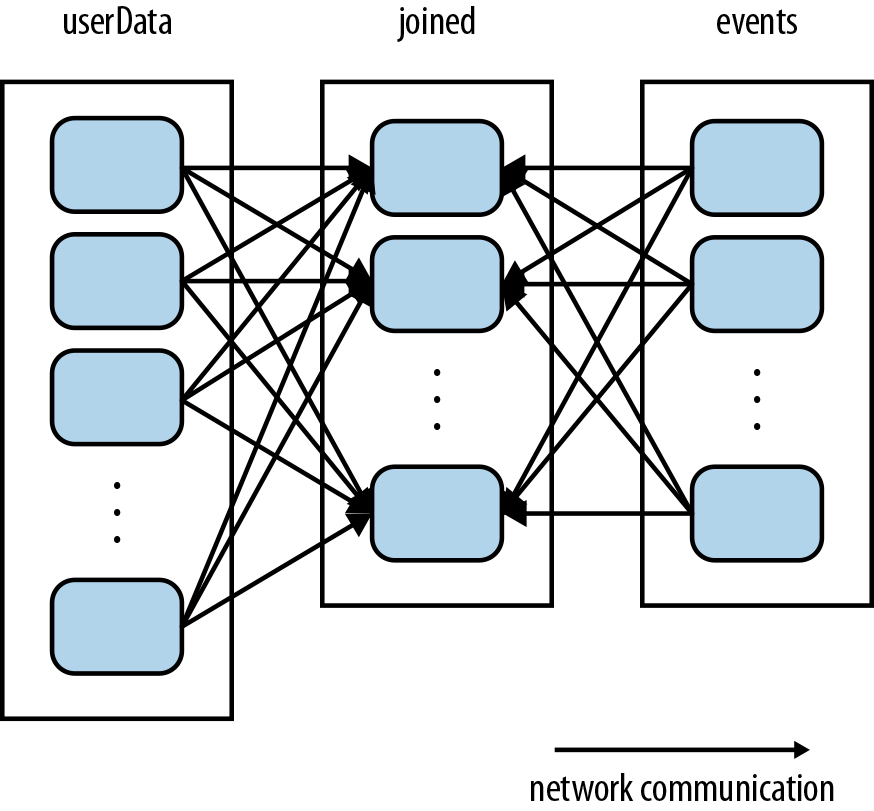
Rešenje je jednostavno. Samo treba upotrebiti partitionBy() transformaciju nad userData. Na taj način stavljamo Sparku do znanja da ima hash partitioner na jednom od rdd-ova i da pri join() treba da to ima u vidu.
userData = sc.textFile("korisnici.txt").map(lambda x: (x.split(" ")[0], x.split(" ")[1:])).partitionBy(100).persist()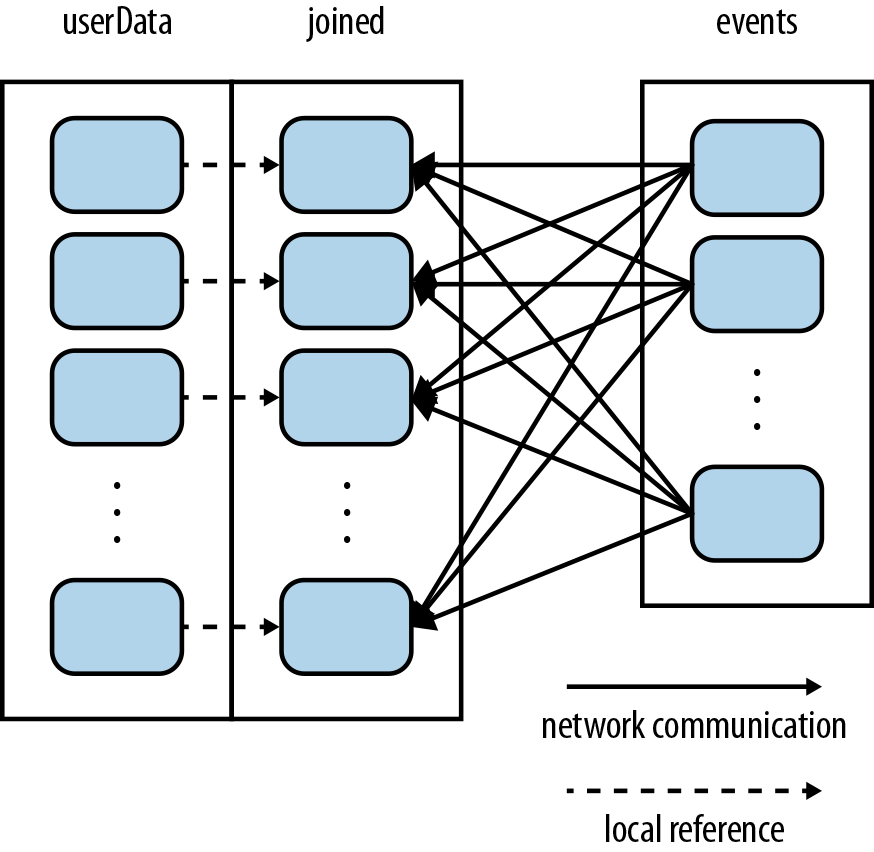
Napisati pyspark skriptu koja aproksimira vrednosti broja primenom Monte Carlo metode.
Predlog rešenja iz pyspark-shell
>>> from random import random
>>> from operator import add
>>> partitions = 10
>>> n = 1000000 * partitions
>>> def f(_):
... x = random() * 2 - 1
... y = random() * 2 - 1
... return 1 if x * x + y * y <= 1 else 0
...
>>> countRdd = sc.range(1, n+1, 1, partitions).map(f)
>>> count = countRdd.reduce(add)
>>> print("Pi is %f" % (4.0 * count / n))