
 Uvod
Uvod
Apache Spark je platforma za klaster računare dizajnirana da bude brza i opšte namene.
Što se tiče brzine, Spark proširuje popularni MapReduce model da bi podržao više tipova operacija, uključujući interaktivne upite i procesuiranje tokovo podataka (streaming). Glavna karakteristika Sparka je mogućnost da se preračunavanje izvode u radnoj memoriji, ali je sistem efikasniji od klasičnog MapReduce modela i u složenim aplikacijama koje koriste podatke sa diska.
Opšta namena Spark-a se ogleda u tome što on pokriva širok opseg poslova koji su prethodno zahtevali različite distribuirane sisteme (paketna obrada, iterativni algoritmi i streaming). Podrškom za različite tipove poslova Spark omogućava da se lako kombinuju različiti tipovi procesuiranja.
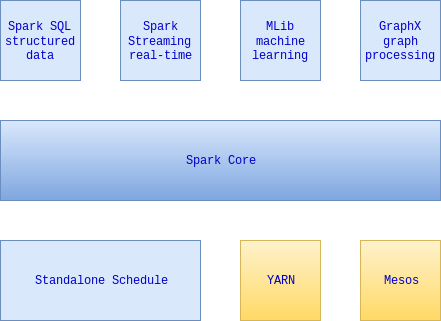
Spark projekat sadrži više komponenti. Jezgro Sparka je je zaduženo za raspoređivanje, distribuiranje i nadgledanje aplikacija koji se sastoje od mnogo zadataka koji se izvršavaju na mnogo mašina. Jezgro pokreće više komponenti višeg nivoa specijalizovanih za različite vrste obrade podataka, kao što su SQL ili mašinsko učenje. Ove komponente su kreiranje da blisko sarađuju, pa mogu da se kombinuju kao biblioteke u aplikativnom projektu.
Filozofija takve integracije ima više korisnih posledica. Prvo, sve biblioteke i komponente višeg nivoa imaju korist ako se unapređuju komponente nižeg nivoa. Na primer, kada se Spark jezgro dodatno optimizuje tada i SQL komponenta i komponenta za mašinsko učenje ima korist od te optimizacije. Takođe, troškovi pokretanja celog Sparka su manji nego pokretanje 5 do 10 različitih softverskih rešenja. Ovi troškovi uključuju implementaciju, održavanje, testiranje, podršku i drugo.
Na kraju, najznačajnija prednost bliske integracije je mogućnost pravljenja aplikacije koja kombinuje, naizgled različite, komponente. Na primer, u Spark-u može da se piše jedna aplikacija koja koristi mašinsko učenje za klasifikovanje podataka koji u realnom vremenu koriste podatke sa nekog stream-a podataka. Istovremeno, nad rezultatima mogu da se, preko SQL-a, vrše upiti.
Spark poseduje interaktivni shell koji omogućava ad hoc analizu podataka. Za razliku od većine drugih shell-ova, koji manipulišu podacima koristeći memoriju i disk jedne mašine, Spark shell dozvoljava interakciju sa podacima koji su distribuirani na diskovima ili memoriji svih računara na klasteru. Spark se brine o automatskoj distribuciji ovog procesa.
Prvi korak je pokretanje Spark shell-a. Za Python Spark shell se zove pyspark i nalazi se u bin poddirektorijumu Spark direktorijuma.
U Spark-u preračunavanja se vrše preko operacija nad distribuiranom kolekcijom podataka koja je automatski paralelizovana na svim čvorovima klastera. Kolekcija se zove resilient distributed datasets (RDDs).
>>> lines = sc.textFile("README.md") # Kreira RDD koji se zove lines
>>> lines.count() # Koliko elemenata ima RDD
127
>>> lines.first() # Prvi clan RDD-a ili prva linija fajla README.md
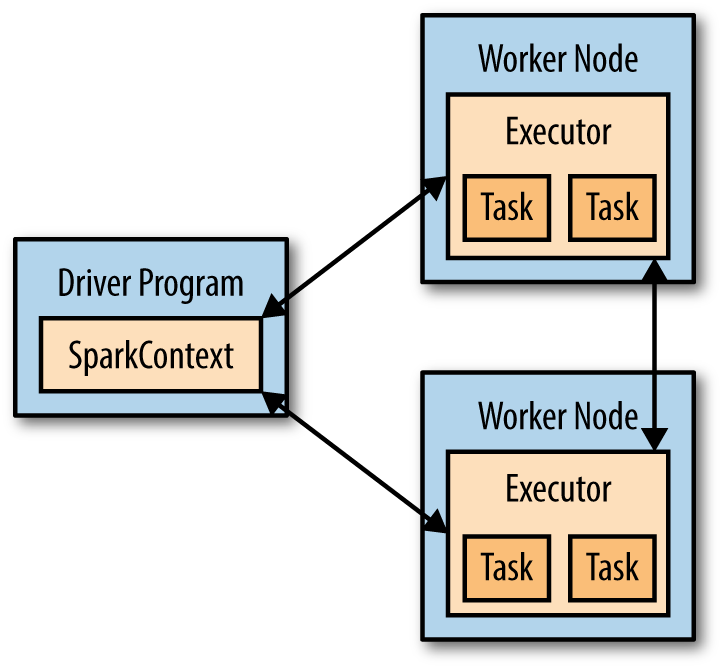
u'# Apache Spark'Na visokom nivou, svaka Spark aplikacija sadrži driver program koji izvršava različite paralelne operacije na klasteru. Driver program ima main funkciju i definiše RDD-ove na klasteru, a zatim primenjuje operacije nad njima. U prethodnom primeru driver program je Spark shell.
Driver program pristupa Sparku preko SparkContext objekta, koji reprezentuje konekciju ka klasteru. Spark Shell automatski kreira SparkContext u promenljivoj sc. Funkcijom sc.textFile() koristeći SparkContext, kreirali smo RDD koji reprezentuje linije tekstualnog fajla. Nad RDD-om mogu da se izvrše razne operacije npr. count().
Da bi izvršio operacije, driver program obično upravlja većim brojem nodova preko alata koji se zove executor. Na primer, ako pokrenemo count() opraciju na klasteru, različite mašine mogu da broje linije u različitim delovima fajla.
Veliki deo Spark api-ja je zadužen za posao prosleđivanja funkcija u opratore da bi mogli da se izvrše na klasteru. Na primer mogli bi da proširimo prethodni primer da filtrira linije koje sadrže reč Python.
>>> pythonLines = lines.filter(lambda line: "Python" in line)
>>> pythonLines.first()
u'## Interactive Python Shell'Poziv filter() ili bilo kog drugog operatora koji prima funkciju kao argument, takođe paralelizuje prosleđenu funkciju na klasteru tj. Spark automatski uzima funkciju (lines.contains(“Python”)) i prosleđuje je u executor čvorova. Ovo za posledicu ima da je moguće da jedan driver program ima delove koji se automatski izvršavaju na više čvorova.
Da bi napisali Spark aplikaciju u Python-u dovoljno je napisati Spark program kao Python skriptu i pokrenuti preko spark-submit alata koji se nalazi u poddirektorijumu bin spark direktorijuma.
$ spark-submit my_script.pySpark-submit je skripta koja postavlja okruženje tako da Spark Python API može da funkcioniše. Kada je neka naša skirpta povezana sa Sparkom potrebno je importovati Spark pakete u program i kreirati SparkContext. To se postiže tako što se prvo kreira SparkConf objekat koji konfiguriše aplikaciju i onda se kreira SparkContext preko SparkConf objekta.
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)Primer pokazuje šta je najmanje potrebno da bi se inicijalizovao SparkContext.
setMaster() kao argument prima URL klastera. Ako je argument “local” Spark se nalazi na lokalnoj mašini.setAppName kao argument prima ime aplikacije. Ovo ime se koristi kao identifikator aplikacije na klasteru.Sav posao koji Spark obavlja, ugrubo, možemo podeliti u tri kategorije:
U pozadini, Spark automatski distribuira podatke koji se nalaze u RDD-u na čvorove klastera i paralelizuje operacije koje se izvršavaju nad njim.
Korisnik može da kreira RDD na dva načina – distribuiranjem kolekcije objekata (liste ili skupa) ili učitavanjem spoljneg skupa podataka u driver program. U prethodnom primeru je prikazano učitavanje podataka iz tekstualnog fajla korišćenjem funkcije SparkContext.textFile().
Jednom kreiran, RDD nudi dve vrste operacija: transformacije i akcije. Tranformacije konstruišu novi RDD iz prethodnog. Primer je korišćenje f-je filter(). Akcije preračunavaju rezultat na osnovu RDD i rezultat vraćaju ili u driver program ili u spolji uređaj za smeštanje podataka. Primer je f-ja first().
Transformacije i akcije se razlikuju po načinu na koji ih Spark tretira. Iako je moguće definisati novi RDD u bilo kom trenutku, Spark preračunava RDD u lenjom obliku (lazy) tj. kreira se RDD tek kada je nad njim prvi put izvršena akcija. Ovaj pristup, iako čudan na prvi pogled, u stvari ima dosta smisla. Analizirajmo primer koji smo prethodno koristili (učitavanje tekstualnog fajla i filtriranje linija koje sadrže reč Python). Ako bi Spark učitao i uskladištio podatke u trenutku kada napišemo lines = sc.textFile() potrošio bi prilično prostora budući da nakon toga odmah koristimo filtriranje koje eliminiše mnogo linija. Spark, jednom kada vidi ceo niz transformacija, može da preračuna koji podaci su potrebni za krajnji rezultat i samo njih da učita. Ako koristimo first() akciju, Spark će da skenira fajl samo dok ne pronađe prvu odgovarajuću liniju, ne čitajući ostatak fajla.
Spark RDD po default-u se preračunava svaki put kada se izvrši akcija nad njim. Ako želimo da iskoristimo isti RDD nad više akcija možemo da zamolimo Spark da zadrži RDD u memoriji koristeći RDD.persist(). Nakon prve akcije Spark će da zadrži RDD sadržaj u memoriji (particionisan na više mašina u klasteru) i koristiće ga u budućim akcijama. Zadržavanje RDD je moguće i na disku umesto u memoriji.
Najjednostavnije moguće je kreirati RDD iz postojeće kolekcije u programu koju je potrebno proslediti u parallelize() f-ju SparkContext-a.
lines = sc.parallelize(["pandas", "i like pandas"])Način koji se više koristi je kreiranje RDD-a učitavanjem podataka iz sekundarne memorije. Spark podržava širok opseg ulaznih i izlaznih izvora. Može da pristupi podacima preko InputFormat i OutputFormat interfejsa koji koristi i Hadoop MapReduce model i koji koristi mnoge fajl formate i sisteme za sklaištenje podataka (S3, HDFS, Cassandra, Hbase isl.).
Za podatke koji se nalaze u lokalnom ili distribuiranom fajl sistemu, npr. HDFS, NFS ili Amazon S3, Spark može da pristupi različitim tipovima fajlova uključujući tekstualne, JSON, SequencFiles i protokol baferima. Spark SQL modul obezbeđuje API za struktuiranje izvore podataka uključujući JSON i Apache Hive. Takođe, za baze podataka i ključ/vrednost skladišta postoje biblioteke koje se povezuju na Cassandra, Hbase, Elasticsearch i JDBC bazu.
| Ime formata | Struktirani | Komentar |
|---|---|---|
| Tekstualni fajl | Ne | Linije predstavljaju slogove podataka. |
| JSON | Delimično | Veći biblioteka zahteva jedan slog po liniji. |
| CSV | Da | |
| SequenceFiles | Da | Hadoop fajl format koji koristi key/value podatke |
| Protocol Buffers | Da | Brz, višejezični format |
| Object fajl | Da | Koristan za pamćenje iz Spark poslova koji koriste zajednički kod. Oslanja se na Java Serializaciju. |
input = sc.textFile("file:///home/holden/repos/spark/README.md")Ako se podaci nalaze u više fajlova unutar jednog direktorijuma postoje dva načina za njihovo učitavanje. Prvo korištćenjem textFile() funkcije kojoj kao argument prosleđujemo putanju do direktorijuma. Tako će se formirati RDD od sadržaja svakog fajla unutar direktorijuma. Nekada je potrebno da se zna iz kog fajlu koji deo ulaza je došao. Ako su fajlovi pojedinačno mali onda može da se koristi SparkContext.wholeTextFiles() kojim se dobija RDD koji kao ključ ima naziv fajla.
Da bi smo zapamtili rezultat koristimo f-ju saveAsTextFile()
result.saveAsTextFile(output)Output je direktorijum i Spark će ispisati više fajlova unutar tog direktorijuma. Ovo omogućava Sparku da upisuje podatke iz više čvorova.
Učitavanje
import json
data = input.map(lambda x: json.loads(x))Pamćenje
(data.filter(lambda x: x['lovesPandas']).map(lambda x: json.dumps(x)).saveAsTextFile(ouptuFile))Učitavanje
import csv
import StringIO
...
def loadRecord(line):
"""Parse a CSV line"""
input = StringIO.StringIO(line)
reader = csv.DictReader(input, fieldnames=["name", "favouriteAnimal"])
return reader.next()
input = sc.textFile(inputFile).map(loadRecord)Pamćenje
def writeRecords(records):
"""Write out CSV lines"""
output = StringIO.StringIO()
writer = csv.DictWriter(output, fieldnames=["name", "favoriteAnimal"])
for record in records:
writer.writerow(record)
return [output.getvalue()]
pandaLovers.mapPartitions(writeRecords).saveAsTextFile(outputFile)| map(func) | Povratna vrednost novi RDD formiran tako što je svaki element izvornog RDD prosleđen f-ji func. |
| flatMap(func) | Slično kao i map, ali svaki ulazni element može da se mapira na 0 ili više izlaznih elemenata. |
| filter(func) | Novi RDD koji se sastoji samo od elemenata koji prolaze uslov u f-ji func |
| distinct() | Uklanja duplikate. |
| sample(withReplacement, fraction, [seed]) | Slučajno uzorkuje RDD, sa ili bez ponavljanja, verovatnoćom fraction. |
U primerima funkcija collect() je akcija koja je objašnjenja kasnije, trenutno služi za prikaz podataka iz RDD-a.
>>> sc.parallelize([3,4,5]).map(lambda x: range(1, x)).collect()
[[1, 2], [1, 2, 3], [1, 2, 3, 4]]
>>> sc.parallelize([3,4,5]).flatMap(lambda x: range(1, x)).collect()
[1, 2, 1, 2, 3, 1, 2, 3, 4]
>>> sc.parallelize([3,4,5]).map(lambda x: [x, x*x]).collect()
[[3, 9], [4, 16], [5, 25]]
>>> sc.parallelize([3,4,5]).flatMap(lambda x: [x, x*x]).collect()
[3, 9, 4, 16, 5, 25]
sc.parallelize([3,4,5]).flatMap(lambda x: [x+1]).collect()
[4, 5, 6]
>>> sc.parallelize([3,4,5]).flatMap(lambda x: x+1).collect() #?
>>> sc.parallelize([3,4,5]).map(lambda x: x+1).collect()
[4, 5, 6]greetings.txt
Good Morning
Good Evening
Good Day
Happy Birthday
Happy New Year>>> lines = sc.textFile("greetings.txt")
>>> lines.map(lambda line: line.split()).collect()
[[u'Good', u'Morning'], [u'Good', u'Evening'], [u'Good', u'Day'], [u'Happy', u'Birthday'], [u'Happy', u'New', u'Year']]
>>> lines.flatMap(lambda line: line.split()).collect()
[u'Good', u'Morning', u'Good', u'Evening', u'Good', u'Day', u'Happy', u'Birthday', u'Happy', u'New', u'Year']>>> sc.parallelize([3,4,5,5]).filter(lambda x: x != 3).collect()
[4, 5, 5]
>>> sc.parallelize([3,4,5,5]).distinct().collect()
[4, 5, 3]
>>> sc.parallelize([3,4,5,5]).sample(False, 0.5).collect()
[3, 4]
>>> sc.parallelize([3,4,5,5]).sample(False, 0.5).collect()
[3, 4, 5]
>>> sc.parallelize([3,4,5,5]).sample(False, 0.5).collect()
[4, 5, 5]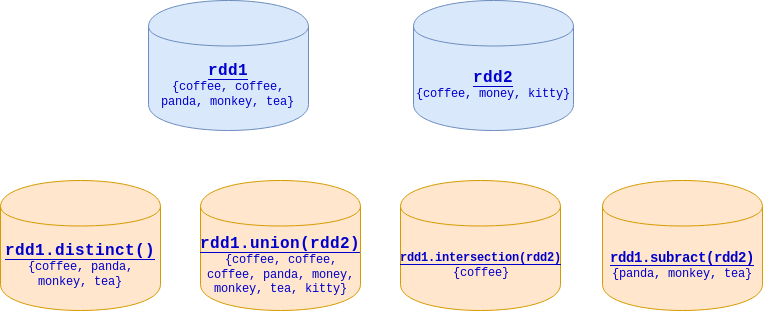
>>> rdd1=sc.parallelize(["coffee", "coffee", "panda", "monkey", "tea"])
>>> rdd2=sc.parallelize(["coffee", "money", "kitty"])
>>> rdd1.distinct().collect()
['tea', 'panda', 'monkey', 'coffee']
>>> rdd1.union(rdd2).collect()
['coffee', 'coffee', 'panda', 'monkey', 'tea', 'coffee', 'money', 'kitty']
>>> rdd1.intersection(rdd2).collect()
['coffee']
>>> rdd1.subtract(rdd2).collect()
['tea', 'panda', 'monkey']
| collect() | Vraća sve elemente iz RDD-a |
| count() | Broj elemenata RDD-a |
| countByValue() | Broj pojavljivanja svakog elementa u RDD-u. |
| take(num) | Vraća num elemenata iz RDD-a. |
| top(num) | Vraća prvih num elemenata iz RDD-a. |
| takeOrdered(num)(ordering) | Vraća najboljih num elemenata sortiranih po f-ji ordering |
| takeSample(withReplacement, num, [seed]) | Vraća num nasumično izabranih elemenata. |
| reduce(func) | Kombinuje elemente RDD-a na osnovu f-je func. |
| fold(zero)(func) | Isto kao i reduce() ali može da se prosledi nulta vrednost. |
| aggregate(zero)(seqOp, combOp) | Slično kao reduce() ali se koristi da bi povratna vrednost bila različitog tipa od tipa elemenata. |
| foreach(func) | Primenjuje f-ju func na svaki element RDD-a. |
Funkcija func akcije reduce(func) prima dva argumenta koji su istog tipa kao i elementi RDD-a i povratna vrednost je istog tipa kao i ti elementi. Najjednostavniji primer je sabiranje svih elemenata RDD-a.
>>> sc.parallelize([1,2,3,4]).reduce(lambda x, y: x+y)
10Slično reduce() f-ji je f-ja fold() koja pored f-je prima i nultu vrednost. Nulta vrednost se poziva kao početna vrednost na svakoj particiji podataka. Za sabiranje bi trebala da bude 0, množenje 1, prazna lista za konkatenaciju …
Kod akcija reduce() i fold() povratna vrednost je istog tipa kao i elementi RDD-a. Ovo je pogodno za operacije slične sabiranju, ali nekada je potrebno vratiti promenljive različitog tipa. Na primer, ako želimo da preračunamo prosečnu vrednost elemenata, moramo da vodimo računa i o broju elemenata i o sumi elemenata. Da bi to izveli potrebno je da nam povratna vrednost bude neka lista od dva elementa. Koristeći reduce() ovaj problem možemo da zaobiđemo tako što će mo prvo da koristimo map() i transformišemo svaki element u listu koja sadrži vrednost i broj 1. To je tip koji mi želimo kao povratnu vrednost. Sada možemo da koristimo reduce() nad novim RDD-om.
>>> rdd1=sc.parallelize([1,2,3,4]).map(lambda x: [x, 1])
>>> rdd1.collect()
[[1, 1], [2, 1], [3, 1], [4, 1]]
>>> sumCount=rdd1.reduce(lambda x, y: [x[0] + y[0], x[1] + y[1]])
>>> sumCount
[10, 4]
>>> sumCount[0]/float(sumCount[1])
2.5Funkcija aggregate nas oslobađa ograničenja da povratni tip mora da bude istog tipa kao i elementi RDD-a. F-ja aggregate, kao i fold() prima nultu vrednost i dve f-je. Prva f-ja kombinuje elemente RDD sa akumulatorom. Druga f-ja spaja akumulatore, sa različitih nodova, u jednu vrednost.
>>> sumCount=sc.parallelize([1,2,3,4]).aggregate((0,0),
... (lambda acc, value: (acc[0] + value, acc[1] + 1)),
... (lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1])))
>>> sumCount[0]/float(sumCount[1])
2.5Nekada je korisno izvršiti određenu akciju nad svim elementima RDD-a, ali bez izračunavanja rezultata i njegovog korišćenja u driver program-u. Dobar primer je postavljanje JSON-a na webserver iz RDD-a ili ubacivanje podataka u bazu podataka. U oba slučaja foreach() nam dozvoljava da izvršimo zadatu funkciju nad svakim elementom RDD-a bez skupljanja podataka na lokalnom računaru.